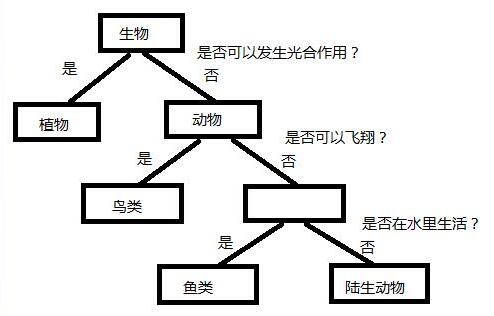
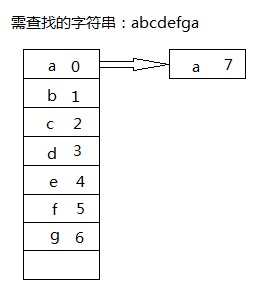
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
| template<typename CharT>
class base64 {
public:
//base64 加密
static bool encode (std::basic_string<charT>& _old, std::basic_string<charT>& _new) {
static charT _code [] = {
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P',
'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f',
'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v',
'w', 'x', 'y', 'z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '+', '/',
};
ptrdiff_t i, len = _old.length ();
_new.resize (((len % 3 ? 1 : 0) + len / 3) * 4);
//主编码循环
for (i = 0; i < len / 3; ++i) {
_new [i * 4] = _code [_old [i * 3] >> 2];
_new [i * 4 + 1] = _code [((_old [i * 3] & 0x03) << 4) | (_old [i * 3 + 1] >> 4)];
_new [i * 4 + 2] = _code [((_old [i * 3 + 1] & 0x0F) << 2) | (_old [i * 3 + 2]) >> 6];
_new [i * 4 + 3] = _code [_old [i * 3 + 2] & 0x3F];
}
//长度不为3的倍数
if (len % 3) {
//第一字节肯定不会溢出,故不检查边界
_new [i * 4] = _code [_old [i * 3] >> 2];
_new [i * 4 + 1] = _code [((_old [i * 3] & 0x03) << 4) | (i * 3 + 1 < len ? _old [i * 3 + 1] >> 4 : 0)];
//倒数第二位可能为'='
if (1 == len % 3)
_new [i * 4 + 2] = '=';
else
_new [i * 4 + 2] = _code [(i * 3 + 1 < len ? (_old [i * 3 + 1] & 0x0F) << 2 : 0)];
//末位肯定为'='
_new [i * 4 + 3] = '=';
}
return true;
}
//base64 解密
static bool decode (std::string& _old, std::string& _new) {
static charT _ucode [] = {
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 62, 0, 0, 0, 63,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 0, 0, 0, 64, 0, 0,
0, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 0, 0, 0, 0, 0,
0, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 0, 0, 0, 0, 0,
};
ptrdiff_t i, len = _old.length ();
ptrdiff_t len2 = len / 4 * 3;
//判断末位是否有等号、有几个等号
if ('=' == _old [len - 2])
len2 -= 2;
else if ('=' == _old [len - 1])
len2--;
else if (len % 4)
len2 += (len % 4 - 1);
_new.resize (len2);
//主解密循环
for (i = 0; i < len2 / 3; ++i) {
_new [i * 3] = (_ucode [_old [i * 4]] << 2) | (_ucode [_old [i * 4 + 1]] >> 4);
_new [i * 3 + 1] = ((_ucode [_old [i * 4 + 1]] & 0x0F) << 4) | (_ucode [_old [i * 4 + 2]] >> 2);
_new [i * 3 + 2] = ((_ucode [_old [i * 4 + 2]] & 0x03) << 6) | (_ucode [_old [i * 4 + 3]]);
}
//末位为一个或两个等号的情况,这时候不能通过主解密循环进行解密
if (len2 % 3) {
_new [i * 3] = (_ucode [_old [i * 4]] << 2) | (_ucode [_old [i * 4 + 1]] >> 4);
if (2 == len % 3)
_new [i * 3 + 1] = ((_ucode [_old [i * 4 + 1]] & 0x0F) << 4) | (_ucode [_old [i * 4 + 2]] >> 2);
}
return true;
}
}; |