1、编码
在讲字符串之前首先说说编码方式。字符串在程序用用数据类型进行存储,同时数据类型存储的也可以是不同编码方式的字符串。总的来说,常用编码方式有以下几种:
ASCII:最古老的编码方式,只使用后7位,可以存储英语大小写、数字及几乎所有常用半角符号。
ISO-8859-1:西欧地区使用的编码方式,兼容ASCII码,在最高位为1时用于描述西文符号。
GB2312/GBK/GB18030:这个是天朝用户专用编码方式,兼容ASCII码,对于英文字符使用1字节进行存储,对于中文使用2字节进行存储,同时两个字节的最高位均为1。值得注意的是,GB2312在Win32开发中常常被称作Ansi编码;其次,GBK为GB2312的扩充,GB18030为GBK的扩充。以前它们是不同的编码方式,但现在也没有严格的划分,通常三者代表同一种编码方式。
BIG-5:也是天朝用户专用编码方式,兼容ASCII码,与GB2312不同的是,它只能编码繁体字,不能编码简体字。
UTF-16/UCS-2:这两个名称所代表的是同一种编码方式,使用两个字节来存储一个中文字符或者一个字母,不兼容ASCII码。这种编码方式也划分为两种不同的子编码方式,分别为UCS-2 Big Endian与UCS2 Little Endian。常说的UTF-16或者UCS-2通常指的是UCS-2 Big Endian。这两种子编码方式的区别为,Big Endian高字节在前,低字节在后;Little Endian低字节在前,高字节在后。这种编码方式在Win32开发中常常被称作Unicode编码,但它属于一种误称;另外,这种编码方式有点浪费存储空间,并且也不能描述世界上所有的符号,相比其他编码,唯一优势是,字符串长度就等于字符个数。
UTF-8:使用最广泛的编码方式,没有之一!几乎所有的网页、XML描述文件、Json数据文件、大多数数据库以及Linux系统均使用的编码方式,相比而言GB2312、UTF-16只有在Windows平台用用而已,仗着Windows平台用的人多,所以也作为常用的编码方式,对于英文字符使用1字节进行存储,因此兼容ASCII编码;它同时也能编码世界上所有的文字,对于汉字而言这种编码方式使用3个字节进行存储,但理论上可以使用2、3、4、5或6字节来编码一个特定字符。
UTF-32/UCS-4:由于UTF-16不能编码所有的编码方式,但发明这编码的人不服,爱搞事,所以发明了4个字节来编码一个字符的编码方式,理论上可以描述世界上所有的字符,但由于一个字母都需要4个字节,过于浪费存储空间,所以这种编码方式几乎没有人使用。
以上是需要了解的编码方式,除了上面几个之外,不同地方也有他们自己的编码方式,以下为不完全统计:
西欧语系:ISO-8859-1
东欧语系:ISO-8859-2
土耳其语:ISO-8859-3
波罗的语:ISO-8859-4
斯拉夫语:ISO-8859-5
阿拉伯文:ISO-8859-6
希腊文:ISO-8859-7
希伯来文:ISO-8859-8
日文:Shift-JIS
韩文:EUC-KR
……
继续阅读C++:字符串编码与字符串
标签: 字符串处理
C++实现高效字符串查找算法
最近想到一个关于高效字符串查找算法的设想,然后果断实现之,算法基于哈希表,用于源字符串特别长的情况,查找的子字符串越长、越没规律,那么速度越快。可能已经有人做过,不过我撸代码前还没听说过类似算法,算是一种轮子吧。
基本实现的思路是:首先建立一个hash_map,然后将子字符串所有字符及位置录入字符串中,如下图所示:
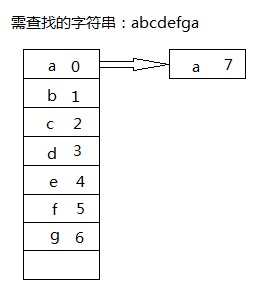
对于需要查找的字符串(比如在很长的字符串文本中查找“abcdefga”这一串字符),构建如上所示哈希表,键值名为子字符串出现的字符,值为出现的位置。
构建好之后呢,就好玩了,我只说说正向查找原理,逆向查找类似。首先,来一个假设,我就假设源字符串为“abababcdefgaaaaa”这样吧,第一次,取源字符串中,(子字符串长度-1)这个位置的字符,值为d,然后取哈希表的值,为3,那么,将源字符串中7-3的位置开始,与子字符串相比较,比较结果较满意,第一次就查找成功,那么直接返回7-3=4。
继续阅读C++实现高效字符串查找算法
C++中std::string实现trim、format等函数
Warning: WP_Syntax::substituteToken(): Argument #1 ($match) must be passed by reference, value given in /www/wwwroot/fawdlstty.com/wp-content/plugins/wp-syntax/wp-syntax.php on line 383
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 | //////////////////////////////////////////////////////////////////////////////// // // File Name: String.hpp // Class Name: hString // Description: 用于字符串相关扩展操作 // Author: Fawdlstty // // Date: Nov 19, 2016 // Log: Create this file. // //////////////////////////////////////////////////////////////////////////////// #ifndef __STRING_HPP__ #define __STRING_HPP__ #include <string> #include <cstdarg> template<typename charT> class hString { public: //清除字符串开始部分空格 static void trimLeft (std::basic_string<charT> &str) { str.erase (0, str.find_first_not_of (' ')); } //清除字符串结束部分空格 static void trimRight (std::basic_string<charT> &str) { str.erase (str.find_last_not_of (' ') + 1); } //清楚两端空格 static void trim (std::basic_string<charT> &str) { str.erase (0, str.find_first_not_of (' ')); str.erase (str.find_last_not_of (' ') + 1); } //删除字符串中指定字符 static void erase (std::basic_string<charT> &str, const charT &charactor) { str.erase (remove_if (str.begin (), str.end (), bind2nd (std::equal_to<charT> (), charactor)), str.end ()); } //替换字符串中指定字符串 static int replace (std::basic_string<charT> &str, const std::basic_string<charT> &strObj, const std::basic_string<charT> &strDest) { int ret = 0; charT pos = str.find (strObj); while (pos != std::basic_string<charT>::npos) { ret++; str.replace (pos, strObj.size (), strDest); pos = str.find (strObj); } return ret; } //一行中的字符串截断,并可转为其他类型 template<typename T> static int split_aLine_conv (const std::basic_string<charT> &str, std::vector<T> &seq, charT separator) { if (str.empty ()) return 0; int count = 0; std::basic_stringstream<charT> bs (str); for (std::basic_string<charT> s; std::getline (bs, s, separator); count++) { typename T val; std::basic_stringstream<charT> bss (s); bss >> val; seq.push_back (val); } return count; } //字符串截断 static void split (std::basic_string<charT> s, std::vector<std::basic_string<charT> >& v, char ch = ' ') { ptrdiff_t start = 0, p, len = s.length (); do { p = s.find (ch, start); if (p == -1) p = len; s [p] = '\0'; if (s [start] != '\0') v.push_back (&s [start]); start = p + 1; } while (start < len); } //字符串格式化 static std::basic_string<charT> format (std::basic_string<charT> fmt_str, ...) { //来源:http://stackoverflow.com/questions/2342162/stdstring-formatting-like-sprintf ptrdiff_t final_n, n = ((ptrdiff_t) fmt_str.size ()) * 2; std::basic_string<charT> str; std::unique_ptr<charT []> formatted; va_list ap; while (1) { formatted.reset (new charT [n]); //strcpy_s (&formatted [0], fmt_str.size (), fmt_str.c_str ()); va_start (ap, fmt_str); final_n = vsnprintf_s (&formatted [0], n, _TRUNCATE, fmt_str.c_str (), ap); va_end (ap); if (final_n < 0 || final_n >= n) n += abs (final_n - n + 1); else break; } return std::basic_string<charT> (formatted.get ()); } }; typedef hString<char> hStringA; typedef hString<wchar_t> hStringW; #ifdef _UNICODE typedef hStringW hString_t; typedef std::wstring string_t; #else typedef hStringA hString_t; typedef std::string string_t; #endif #endif //__STRING_HPP__ |